![]() v1.3-SNAPSHOT
v1.3-SNAPSHOT
Monitoring the Wikipedia Edit Stream
在本章指南中,我们会从头开始学习如何创建一个Flink工程,以及如何在Flink集群上运行一个流计算程序。
维基百科提供了一个 IRC 频道,它记录了所有在 Wiki 上的编辑日志。我们要做的工作是将该频道的数据读入Flink,并计算每个用户在一个给定时间窗口内编辑的字节数。虽然对于Flink来说这是一个很容易就能够实现的场景,但是在你自己动手构建复杂的分析程序之前,学习这个过程能够为你打下良好的基础。
创建Maven工程
我们将使用一个Flink Maven 原型来创建工程结构。如果你想了解更多这方面的内容,请参考 Java API Quickstart 。可以运行下面的命令来创建Maven工程:
$ mvn archetype:generate \
-DarchetypeGroupId=org.apache.flink \
-DarchetypeArtifactId=flink-quickstart-java \
-DarchetypeCatalog=https://repository.apache.org/content/repositories/snapshots/ \
-DarchetypeVersion=1.3-SNAPSHOT \
-DgroupId=wiki-edits \
-DartifactId=wiki-edits \
-Dversion=0.1 \
-Dpackage=wikiedits \
-DinteractiveMode=false你可以根据需要修改 groupId,artifactId 和package 参数。使用上面的命令和参数,Maven 将会创建出一个工程框架,其结构如下所示:
$ tree wiki-edits
wiki-edits/
├── pom.xml
└── src
└── main
├── java
│ └── wikiedits
│ ├── BatchJob.java
│ ├── SocketTextStreamWordCount.java
│ ├── StreamingJob.java
│ └── WordCount.java
└── resources
└── log4j.properties在根目录下,你会看到有一个已添加了 Flink 依赖的pom.xml 文件,在src/main/java路径下,你会找到几个 Flink 示例程序文件。既然是从头开始学习,我们可以暂时先把这些示例程序删除:
$ rm wiki-edits/src/main/java/wikiedits/*.java最后,我们需要添加 Flink Wikipedia 连接器依赖以便于我们在程序中使用。编辑pom.xml文件的dependencies部分,修改完成后应该像下面一样:
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-wikiedits_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
</dependencies>我们可以看到 pom.xml 文件中已经加入了flink-connector-wikiedits_2.11依赖。(本示例及Wikipedia 连接器的灵感来自于 Apache Samza Hello Samza 示例)
编写 Flink 程序
现在,打开你最喜欢的 IDE,我们要开始写代码了。导入 Maven 工程后,创建 src/main/java/wikiedits/WikipediaAnalysis.java 文件:
package wikiedits;
public class WikipediaAnalysis {
public static void main(String[] args) throws Exception {
}
}这个程序现在看起来非常简单,我们会逐步完善它。注意在这里我们不需要手写 import 声明, 因为 IDE 会自动添加。在本小结的结束,我会展示包含 import 声明的完整代码,如果你想跳过前面的部分,也可以直接将完整的代码拷贝到你的 IDE 编辑器中。
在Flink程序中首先需要创建一个StreamExecutionEnvironment(如果你在编写的是批处理程序,需要创建ExecutionEnvironment),它被用来设置运行参数。当从外部系统读取数据的时候,它也被用来创建源(sources)。所以让我们在 main 函数中添加下面的代码:
StreamExecutionEnvironment see = StreamExecutionEnvironment.getExecutionEnvironment();接下来我们要开始添加读取 Wikipedia IRC 日志的源(sources)了:
DataStream<WikipediaEditEvent> edits = see.addSource(new WikipediaEditsSource());它创建了一个包含WikipediaEditEvent元素的DataStream,也是我们需要进一步处理的对象。在本节的案例中,我们关心的是每个用户在一个特定时间窗口内(比如说5秒钟)增加或者删除内容的字节数。为了实现这个目标,我们需要指定用户名作为数据流的 key 字段,也就是说在这个数据流上的操作应该考虑到用户名。在我们的案例中需要对时间窗口中每个唯一用户的编辑字节数求和。为了使数据流包含 key,我们需要提供一个KeySelector, 如下:
KeyedStream<WikipediaEditEvent, String> keyedEdits = edits
.keyBy(new KeySelector<WikipediaEditEvent, String>() {
@Override
public String getKey(WikipediaEditEvent event) {
return event.getUser();
}
});它创建了一个WikipediaEditEvent流,以用户名作为String类型的 key。现在我们可以在这个流上指定窗口并且基于这些窗口内的数据计算出结果。一个窗口指定了要执行计算的数据流的一个分片。当需要在一个无边界的数据流上执行聚合计算时,窗口是必不可少的。在我们的案例中,我们想要做的就是每5秒钟一个窗口对编辑字节数做聚合计算:
DataStream<Tuple2<String, Long>> result = keyedEdits
.timeWindow(Time.seconds(5))
.fold(new Tuple2<>("", 0L), new FoldFunction<WikipediaEditEvent, Tuple2<String, Long>>() {
@Override
public Tuple2<String, Long> fold(Tuple2<String, Long> acc, WikipediaEditEvent event) {
acc.f0 = event.getUser();
acc.f1 += event.getByteDiff();
return acc;
}
});首先调用的.timeWindow()方法指定了我们需要一个大小为5秒钟的滚动窗口(非重叠窗口)。调用的第二个方法指定了对每个窗口分片中每个唯一的key做 Fold transformation 转换。在案例中,我们以初始值("", 0L)为基础,将给定时间窗口内特定用户内容编辑字节数做累加。现在我们从每个大小为5秒的窗口中获取了针对每个用户的结果流,该结果流的元素类型为Tuple2<String, Long>。
现在唯一需要做的就是将结果流在终端输出,并且开始执行计算:
result.print();
see.execute();最后调用执行的操作对启动 Flink Job 来说是必需的。像前面的创建数据源,转换和 Sinks 操作仅仅是构建了一个内部操作图。只有当execute()被调用的时候,这个操作图才会被扔在集群或者在你的本地机器运行。
到目前为止,完整的代码如下:
package wikiedits;
import org.apache.flink.api.common.functions.FoldFunction;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.connectors.wikiedits.WikipediaEditEvent;
import org.apache.flink.streaming.connectors.wikiedits.WikipediaEditsSource;
public class WikipediaAnalysis {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment see = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<WikipediaEditEvent> edits = see.addSource(new WikipediaEditsSource());
KeyedStream<WikipediaEditEvent, String> keyedEdits = edits
.keyBy(new KeySelector<WikipediaEditEvent, String>() {
@Override
public String getKey(WikipediaEditEvent event) {
return event.getUser();
}
});
DataStream<Tuple2<String, Long>> result = keyedEdits
.timeWindow(Time.seconds(5))
.fold(new Tuple2<>("", 0L), new FoldFunction<WikipediaEditEvent, Tuple2<String, Long>>() {
@Override
public Tuple2<String, Long> fold(Tuple2<String, Long> acc, WikipediaEditEvent event) {
acc.f0 = event.getUser();
acc.f1 += event.getByteDiff();
return acc;
}
});
result.print();
see.execute();
}
}你可以在你的 IDE 或者命令行下使用 Maven 运行示例:
$ mvn clean package
$ mvn exec:java -Dexec.mainClass=wikiedits.WikipediaAnalysis其中第一个命令用来构建工程、第二个命令运行 mian 函数。示例的输出应该跟下面的类似:
1> (Fenix down,114)
6> (AnomieBOT,155)
8> (BD2412bot,-3690)
7> (IgnorantArmies,49)
3> (Ckh3111,69)
5> (Slade360,0)
7> (Narutolovehinata5,2195)
6> (Vuyisa2001,79)
4> (Ms Sarah Welch,269)
4> (KasparBot,-245)每行的第一个数字代表打印 Sink 输出所在的并行实例号。
通过以上的学习应该可以让你编写自己的 Flink 程序了。你可以通过阅读 basic concepts 和 DataStream API 获取更多知识. 如果你想学习如何自己建立一个 Flink 集群并将结果写入 Kafka,那需要坚持学习完下面的章节。
额外的练习:集群运行任务和结果写入Kafka
在我们开始之前,请分别参考 setup quickstart 和 Kafka quickstart 在你的机器上部署好 Flink 和 Kafka。
首先,为了能够使用 Kafka Sink,我们需要添加 Flink Kafka 连接器依赖。将此依赖添加在pom.xml文件的 dependencies 部分:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka-0.8_2.11</artifactId>
<version>${flink.version}</version>
</dependency>接下来,我们需要修改我们的代码。我们把 print() Sink 移除,使用 Kafka Sink 替代。修改后的代码如下所示:
result
.map(new MapFunction<Tuple2<String,Long>, String>() {
@Override
public String map(Tuple2<String, Long> tuple) {
return tuple.toString();
}
})
.addSink(new FlinkKafkaProducer08<>("localhost:9092", "wiki-result", new SimpleStringSchema()));同时还需要导入相关的类:
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer08;
import org.apache.flink.streaming.util.serialization.SimpleStringSchema;
import org.apache.flink.api.common.functions.MapFunction;需要关注下我们是怎样通过使用 MapFunction 将Tuple2<String, Long>流转换为String流的。我们之所以做这样的转换是因为将普通字符串格式的数据写入 Kafka 会更容易。然后,我们创建了 Kafka Sink。在代码里,需要将 hostname 和 port 替换成你所安装环境的实际参数。wiki-result是 Kafka topic的名字,在运行程序之前,我们需要创建它。通过 Maven 构建该工程,在集群上运行需要该工程编译后的可执行jar包:
$ mvn clean package编译好的 jar 包在 工程的 target 子目录下: target/wiki-edits-0.1.jar。我们稍后会使用它。
现在我们已经准备好启动 Flink 集群,并且运行 写入 Kafka 的任务了。切换到 Flink 的安装目录,启动本地集群:
$ cd my/flink/directory
$ bin/start-local.sh我们还需要创建 Kafka Topic, 我们的程序需要将数据写入里面:
$ cd my/kafka/directory
$ bin/kafka-topics.sh --create --zookeeper localhost:2181 --topic wiki-results现在让我们在 Flink 本地集群上运行之前生成的 jar 包:
$ cd my/flink/directory
$ bin/flink run -c wikiedits.WikipediaAnalysis path/to/wikiedits-0.1.jar如果一切正常的话,我们的任务运行输出应该跟下面的内容类似:
03/08/2016 15:09:27 Job execution switched to status RUNNING.
03/08/2016 15:09:27 Source: Custom Source(1/1) switched to SCHEDULED
03/08/2016 15:09:27 Source: Custom Source(1/1) switched to DEPLOYING
03/08/2016 15:09:27 TriggerWindow(TumblingProcessingTimeWindows(5000), FoldingStateDescriptor{name=window-contents, defaultValue=(,0), serializer=null}, ProcessingTimeTrigger(), WindowedStream.fold(WindowedStream.java:207)) -> Map -> Sink: Unnamed(1/1) switched to SCHEDULED
03/08/2016 15:09:27 TriggerWindow(TumblingProcessingTimeWindows(5000), FoldingStateDescriptor{name=window-contents, defaultValue=(,0), serializer=null}, ProcessingTimeTrigger(), WindowedStream.fold(WindowedStream.java:207)) -> Map -> Sink: Unnamed(1/1) switched to DEPLOYING
03/08/2016 15:09:27 TriggerWindow(TumblingProcessingTimeWindows(5000), FoldingStateDescriptor{name=window-contents, defaultValue=(,0), serializer=null}, ProcessingTimeTrigger(), WindowedStream.fold(WindowedStream.java:207)) -> Map -> Sink: Unnamed(1/1) switched to RUNNING
03/08/2016 15:09:27 Source: Custom Source(1/1) switched to RUNNING
从上面的输出中你能看到 operators 是如何启动执行的。在该案例中只有两个 operator,因为由于性能的原因,windows 操作之后的 operator 合并成了一个。在 Flink 中我们把它叫做chaining。
你可以通过 Kafka console consumer,在之前创建的 topic 中观察程序的输出:
bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic wiki-result你也可以通过 http://localhost:8081 链接查看 Flink 的控制页面。在上面可以看到 Flink 集群资源和运行任务的概览:
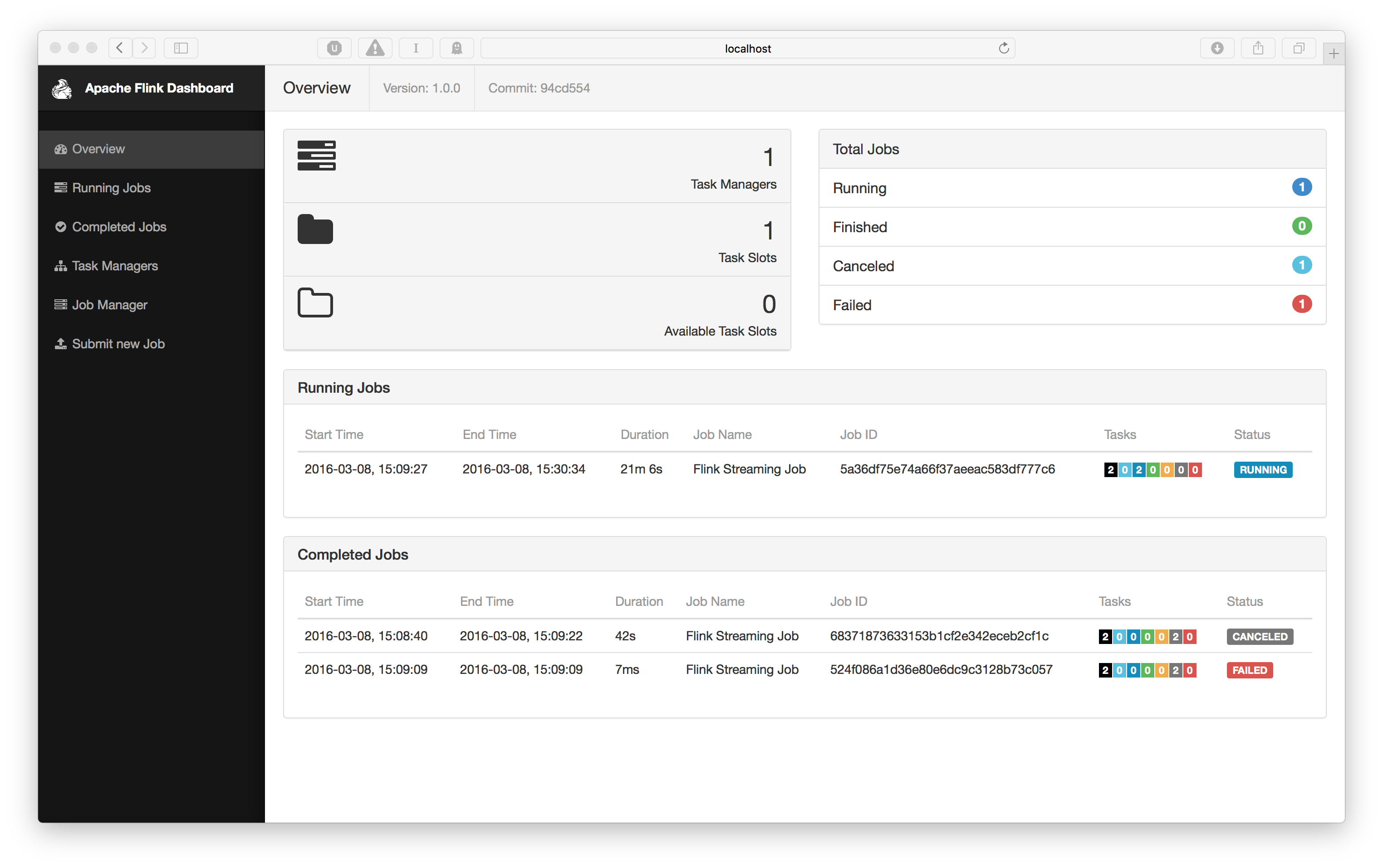
如果你点击了正在运行的任务,会链接到一个页面,在上面你能够查看每个单独的 operator 情况,例如:查询到已经处理的数据条数等信息。
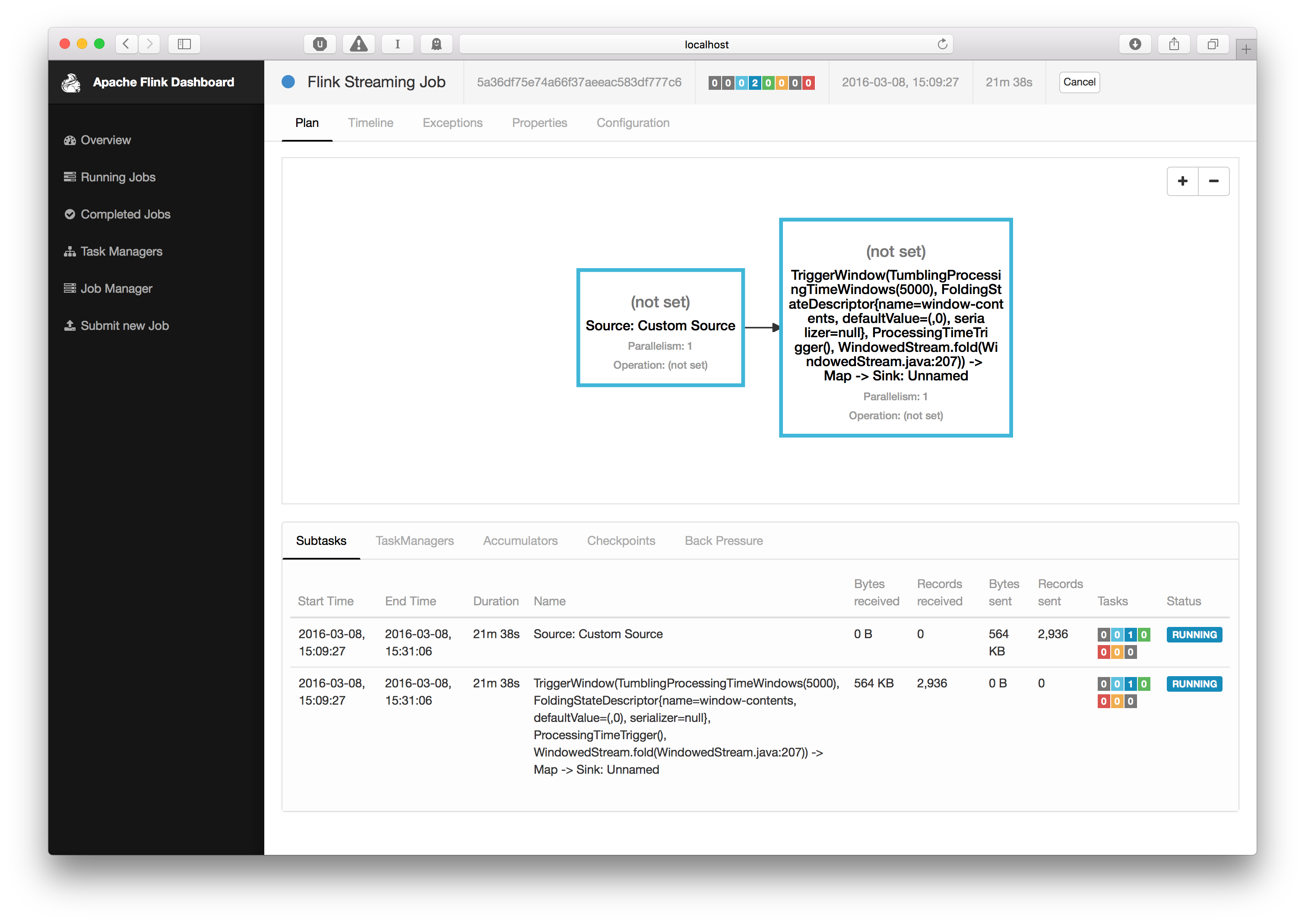
至此我们结束了Flink的小小旅程。 如果还有其他的问题,欢迎你在 Mailing Lists 中进行咨询。